Data
配列・変数などのデータを取り扱うアクション一覧です。
CreateList
概要
CreateListは、リストを作成するアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| items* | 配列 | 作成するリスト | ["夏目漱石","太宰治","三島由紀夫","川端康成"] |
リストビルダーを使ってリストを作成する
複数のアウトプットをリストに追加したい場合は、パラメーター右のメニューから「アウトプットからリストを作成する」を選択すると、簡単にリストを作成することもできます。
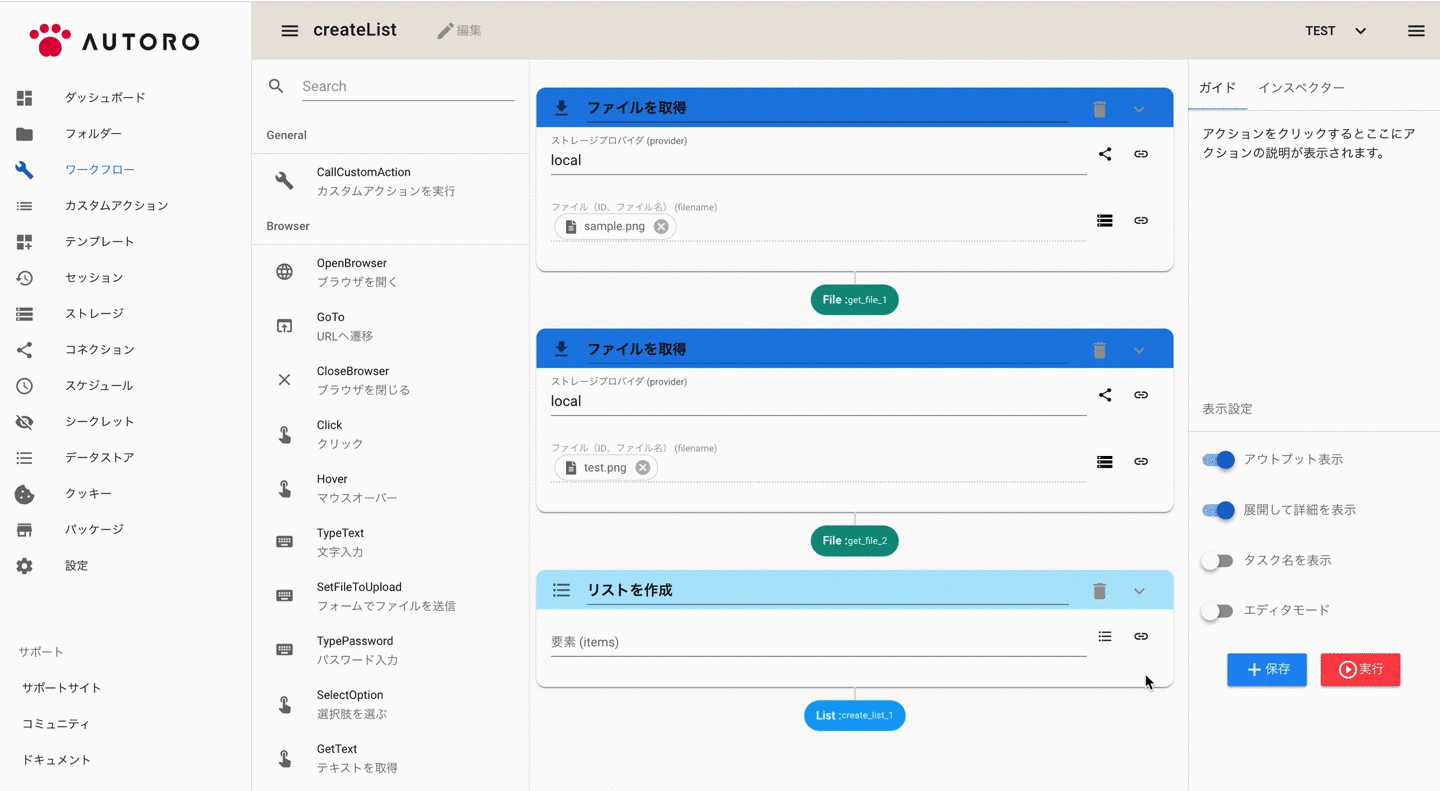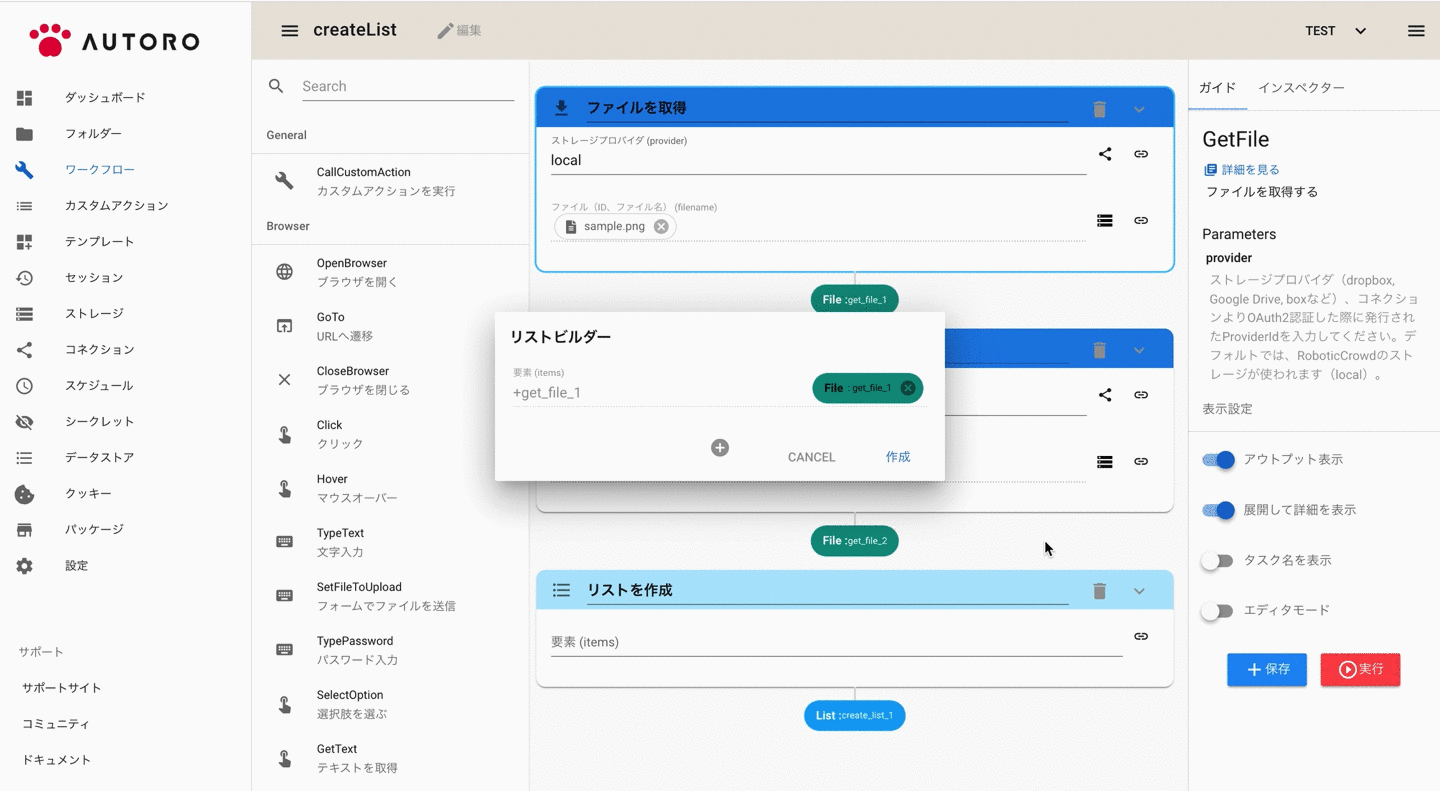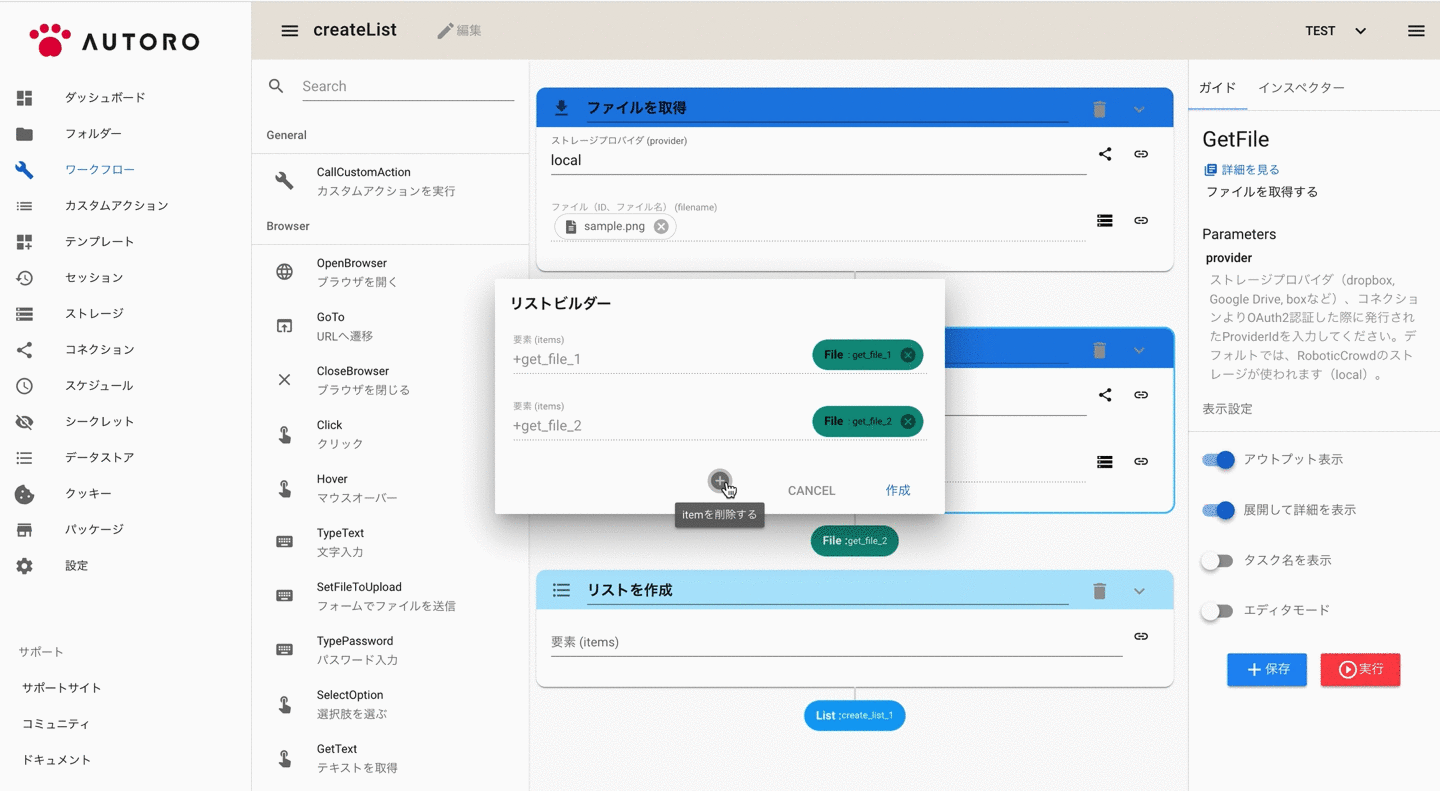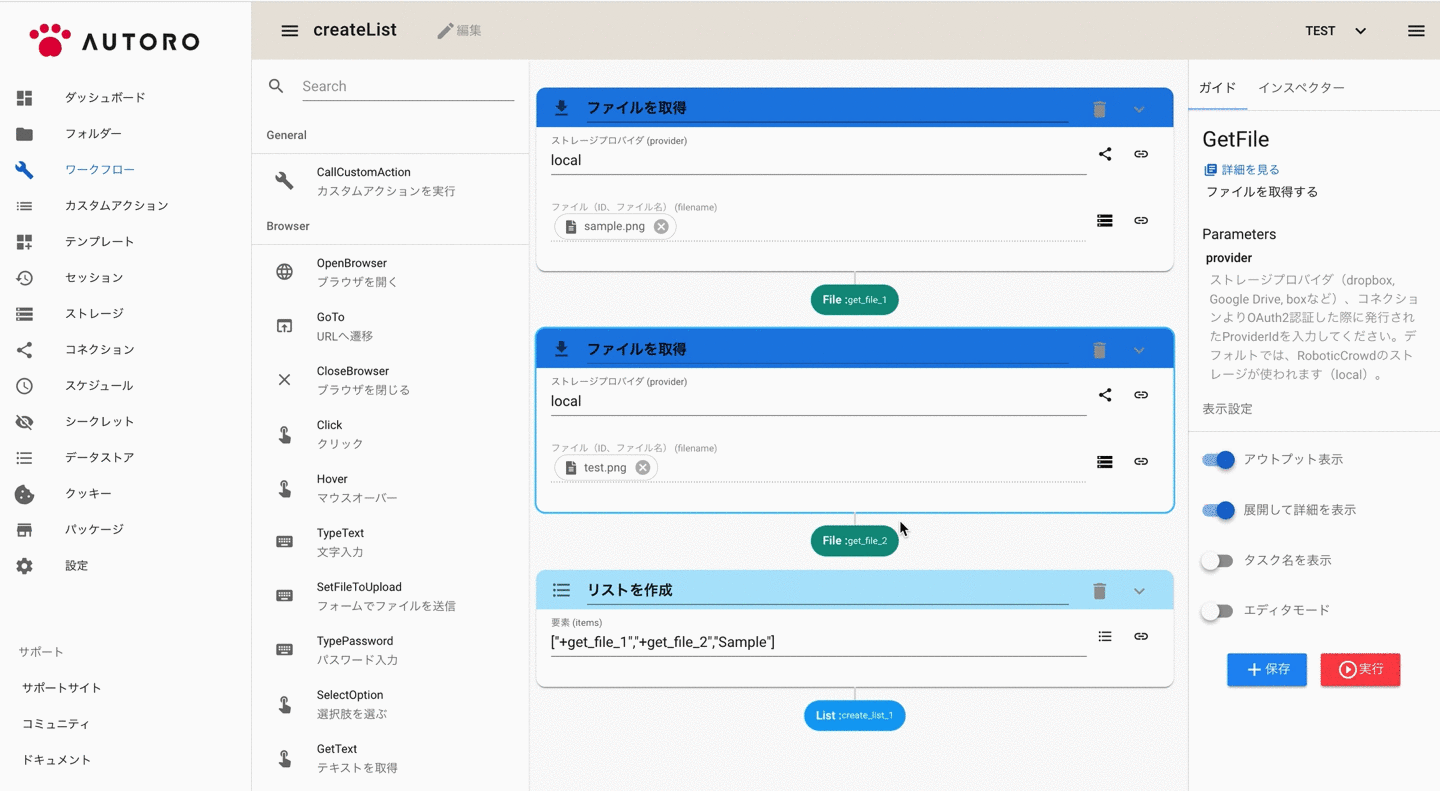
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| List | 配列 | 作成したリスト | ["夏目漱石","太宰治","三島由紀夫","川端康成"] |
使用例
+create_list_1:
action>: CreateList
items: ["夏目漱石","太宰治","三島由紀夫","川端康成"]
# => ["夏目漱石","太宰治","三島由紀夫","川端康成"]
CreateObject
概要
CreateObjectは、オブジェクトを作成するアクションです。keysパラメータを設定すると、各キーの型を指定することができます。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| object* | オブジェクト | 作成するオブジェクト | {"id":123,"name":"taro","mail":"taro@co.jp"} |
| keys | 配列 | 各キーの型を指定する場合は、配列で記載 | [["id","integer"],["name","string"]] |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| JSON | JSON形式 | 作成したオブジェクト | {"id":123,"name":"taro","mail":"taro@co.jp"} |
使用例
+create_object_1:
action>: CreateObject
object:
id: 123
name: taro
mail: 'taro@co.jp'
keys: [["id","integer"],["name","string"]]
# => {
# "id": 123,
# "name": "taro",
# "mail": "taro@co.jp"
#}
GetItemFromList
概要
GetItemFromListは、リストから要素の場所を指定して値を取得するアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| list* | 配列 | 対象のリスト | ["夏目漱石","太宰治","三島由紀夫","川端康成"] |
| index* | 数値 | 取り出したい要素のインデックス(0から始まる) | 1 |
アクションのアウトプットを list に指定し、ピッカーで index を選択する
アクションのアウトプットを list に指定し、ピッカーで index を選択する場合、入力するアクションが実行済みである必要があります。
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 返却された値による | 取り出した要素 | "太宰治" |
使用例
+get_item_from_list_1:
action>: GetItemFromList
list: ["夏目漱石","太宰治","三島由紀夫","川端康成"]
index: 1
# => "太宰治"
GetValueWithKey
概要
GetValueWithKeyは、オブジェクトからキーを指定して値を取得するアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| object* | オブジェクト | 対象のオブジェクト | {"author":"夏目漱石","title":"我輩は猫である"} |
| key* | 文字列 | キー | author |
アクションのアウトプットを object に指定し、ピッカーで key を選択する
アクションのアウトプットを object に指定し、ピッカーで key を選択する場合、入力するアクションが実行済みである必要があります。
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 返却された値による | キーの値 | "夏目漱石" |
使用例
+get_value_with_key_1:
action>: GetValueWithKey
object:
author: '夏目漱石'
title: '我輩は猫である'
key: author
# => "夏目漱石"
ネストされたオブジェクトの値を取り出す
+get_value_with_key_1:
action>: GetValueWithKey
object:
user:
id: 12345
name: '氏名'
key: 'user.id'
# => "12345"
配列を含むオブジェクトの値を取り出す
+get_value_with_key_1:
action>: GetValueWithKey
object:
user:
name: '氏名'
devices:
- type: 'スマートフォン'
- type: 'タブレット'
key: 'user.devices[0]'
# => { "type": "スマートフォン" }
JoinList
概要
JoinListは、リストの要素を文字列として結合するアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| list* | 配列 | 結合するリスト | ["夏目漱石","太宰治","三島由紀夫","川端康成"] |
| separator* | 文字列 | 結合区切り文字 | "," |
list についての補足
多次元配列(配列内の配列)の場合は、入れ子になってる配列をフラットにしてから結合します。
+join_list_1:
action>: JoinList
list: [["夏目漱石","太宰治"],["三島由紀夫","川端康成"]]
separator: '/'
# => "夏目漱石/太宰治/三島由紀夫/川端康成"
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Text | 文字列 | 作成されたテキスト | "夏目漱石,太宰治,三島由紀夫,川端康成" |
使用例
+join_list_1:
action>: JoinList
list: ["夏目漱石","太宰治","三島由紀夫","川端康成"]
separator: ','
# => "夏目漱石,太宰治,三島由紀夫,川端康成"
SearchItemFromList
概要
SearchItemFromListは、リスト内を文字列で検索するアクションです。この検索にはワイルドカードが利用できます。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| list* | 配列 | 対象のリスト | ["夏目漱石","太宰治","三島由紀夫","川端康成"] |
| query* | 文字列 | 検索クエリ | 太宰* |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| List | 配列 | 検索にマッチしたもののリスト | ["太宰治"] |
使用例
+search_item_from_list_1:
action>: SearchItemFromList
list: ["夏目漱石","太宰治","三島由紀夫","川端康成"]
query: '太宰*'
# => ["太宰治"]
StoreValue
概要
StoreValueは、変数に値を保存するアクションです。変数は、 ${...} により呼び出しが可能になります。また、同じ変数名に値を保存することで変数の値を更新することができます。nullの値が定義された場合、空の文字列として登録されます。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| key* | 文字列 | 変数名 | time |
| value | 格納する値による | 保存する値 | ${moment().zone("Asia/Tokyo").format("YYYY年MM月DD日")} |
| setIfNotDefined | 真理値 | trueのとき、変数が未定義の場合のみ保存する。falseのとき、常に保存する。 | false |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 返却された値による | keyとvalueがオブジェクト型で返却される | {"time":"2019年3月12日"} |
使用例
ScrapePageアクションで取得した情報をStoreValueアクションで変数に保存する。
+store_value_1:
action>: StoreValue
key: titles
value: +scrape_page_1
setIfNotDefined: false
# => {
# "titles": [
# "決定版猫と一緒に生き残る防災BOOK",
# "牝の猫と女のネコ",
# "通い猫アルフィーの奇跡",
# "猫をよろこばせる本",
# "猫の困った行動解決ハンドブック"
# ]
#}
StoreValueアクションで保存した変数titlesを他アクションで呼び出す
+text_1:
action>: Text
text: ${titles[0]} # 変数を呼び出す際は、${変数名}の形式で記載
setIfNotDefined: false
# => "決定版猫と一緒に生き残る防災BOOK"
変数名の推奨形式
変数名には、半角英数字および半角アンダースコア(_)を利用し、先頭を数字にしない形式をご利用ください。 なお、変数名は大文字と小文字が区別されます。
サポート外の変数名
Error, Promise, Proxyなどの、一部のJavaScriptの組み込みオブジェクトと同じ名前の変数は、変数セットで使用できません。他の変数名をご利用ください。
JavaScriptの組み込みオブジェクトについては、MDN Web Docsの標準組み込みオブジェクトをご参照ください。
GetState
概要
GetState は、ロボットの動作中の状態を取得することができるアクションです。 取得できる状態の種類は、限られています。また、取得されるのは、直前に残っているステートです。新たにステートを変更するアクションがあった場合は、上書きされます。
取得できる状態
| 名前 | 型 | 概要 |
|---|---|---|
| downloads_count | 整数値 | ブラウザアクションのクリックでダウンロードされたファイルの総数 |
| redirect_paths | オブジェクト | クリックやGoToで画面遷移した際に、リダイレクトされたり、途中に表示されたりしたURLの情報 |
| dialog | オブジェクト | 直前に表示されたアラート表示の対応状況を記録しています。 |
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| key* | 文字列 | キー | redirect_paths |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 返却された値による | オブジェクト型で返却される | [{"status": 200, "url":"https://example.com"}] |
使用例
例えば、ページ遷移時に、通常の遷移(クリックやJavaScriptでの遷移)の場合は、200ステータス、サーバー側でリダイレクトされた時は、302など、次のように返却されます。
+get_state_1:
action>: GetState
key: redirect_paths
# これは例えばこのように表示されます
# [
# {
# "status": 200, # ページ自体の遷移
# "url": "https://javascript.redirect.path.example.com/1"
# },
# {
# "status": 302, # サーバー側でリダイレクトされた時
# "url": "https://redirected.path.example.com/1"
# },
# {
# "status": 200,
# "url": "https://javascript.redirect.path.example.com/2"
# }
# ]
+get_state_2:
action>: GetState
key: dialog.message
# これは例えばこのように表示されます
# "使えない文字列が入力されました。"
RunScript
概要
アクション内で、JavaScriptを実行することができます。StoreValueで保存された変数は、同名の変数名でコード内で使用できます。コードはSandbox環境で実行され、利用できるコードは、JavaScriptにBuilt-inされたオブジェクトのみになります。30秒後にTimeoutします。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| code* | 文字列 | 実行したいJavaScriptのコード | ※code例参照 |
code例
ScrapePageアクションで情報を取得し、StoreValueアクションで変数booksに格納した後、RunScriptアクションでbooksの値を整える。
var element = books;
var newBook = [];
for ( let book of element ) {
newBook.push(book.split("\n"));
}
return newBook;
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 返却された値による | RunScriptの結果 | ※使用例のアウトプット参照 |
使用例
+run_script_1:
action>: RunScript
code: 'var element = books; var newBook = []; for ( let book of element ) { newBook.push(book.split("\n")); } return newBook;'
# => [
# [
# "決定版猫と一緒に生き残る防災BOOK",
# "猫びより編集部",
# "http://books.google.co.jp/books?id=a5JSvwEACAAJ&dq=%E7%8C%AB&hl=&source=gbs_api",
# ""
# ],
# [
# "牝の猫と女のネコ",
# "岩井志麻子",
# "https://play.google.com/store/books/details?id=VFgVDgAAQBAJ&source=gbs_api",
v ""
# ],
# [
# "通い猫アルフィーの奇跡",
# "レイチェル・ウェルズ 中西和美",
# "https://play.google.com/store/books/details?id=WhkVDQAAQBAJ&source=gbs_api",
# ""
# ],
# [
# "猫をよろこばせる本",
# "沼田朗",
# "https://play.google.com/store/books/details?id=kcgMBvj8pzgC&source=gbs_api",
# ""
# ],
# [
# "猫の困った行動解決ハンドブック",
# "高崎一哉",
# "http://books.google.co.jp/books?id=Szcc61SiSHYC&dq=%E7%8C%AB&hl=&source=gbs_api",
# ""
# ]
#]
Compare
概要
Compareは、二つの値を比較して真理値を返すアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| subject* | 指定する値による | この値を主語にして比較 | 10 |
| compare_with* | 指定する値による | 主語をこの値と比較 | 100 |
| method* | セレクト | 比較方法を指定 | "より小さい"("LESS_THAN") |
| not* | 真理値 | 反対の結果を返したい場合、trueに設定 | false |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Boolean | 真理値 | 結果が正であれば true | true |
使用例
+compare_1:
action>: Compare
subject: 10
compare_with: 100
method: LESS_THAN
not: false
# => true
配列やオブジェクトの比較について
配列やオブジェクト同士を比較することができます。 配列と数字、配列と文字列など、異なる型同士の比較はできません。 配列の中身と比較したい場合は、Textアクションなどで配列を文字列化してから比較してください。
ConvertTable
概要
ConvertTableは、テーブルデータ(二次元配列)を変換して返すアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| header* | 真理値 | 変換元のテーブルデータにヘッダーが存在する場合は true | true |
| table* | 配列 | 変換元のテーブルデータ | [['name', 'age'],['bob', 10], ['john', 30]] |
| transform* | 配列 | 処理方式を指定 | [{type: 'filter', column: 'age', operator: '>=', operand: 20, include_blank: true}] |
アクションのアウトプットを table に指定し、ピッカーで transform を選択する
アクションのアウトプットを table に指定し、ピッカーで transform を選択する場合、入力するアクションが実行済みである必要があります。
transform についての補足
type は、filter, column, sortColumn から選択します。
● フィルタ指定の場合のトランスフォームオブジェクトの説明
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| type | 文字列 | テーブルデータに対するフィルタリング処理を行う。 | "filter" |
| column | 指定する値による | headerが存在する場合はヘッダー名、存在しない場合は列番号 | "age" |
| operator | 文字列 | 比較演算子。利用できるものは "==", "!=", "<", "<=", ">", ">=", "~", "!~" のみ。 | ">=" |
| operand | 指定する値による | 比較対象の値 | 20 |
| include_blank | 真偽値 | 指定のcolumnが空だった場合の行の扱い方。trueの場合は空のcolumnを含む行を残し、falseの場合は省く。 | true |
operator についての補足
| 比較演算子 | 概要 | 例 |
|---|---|---|
| == | operandと一致する | "bob" == "bob" |
| != | operandと一致しない | "bob" != "john" |
| < | operandに指定した数値より小さい | 20 < 30 |
| <= | operandに指定した数値以下 | 20 <= 30 |
| > | operandに指定した数値より大きい | 40 > 30 |
| >= | operandに指定した数値以上 | 40 >= 30 |
| ~ | operandに指定した文字を含む | "Hello World" ~ "Hello" |
| !~ | operandに指定した文字を含まない | "Hello World" !~ "Japan" |
● カラム指定の場合のトランスフォームオブジェクトの説明
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| type | 文字列 | テーブルデータに対するヘッダー行の追加、ヘッダー名の変更、列の抽出を行う | "column" |
| columns | オブジェクト | keyは処理対象となるヘッダー名もしくは列番号。valueは新しいヘッダー名。ヘッダーが存在しない場合はヘッダー行が追加される。 | {name: '名前',age: '年齢'} |
● ソートカラム指定の場合のトランスフォームオブジェクトの説明
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| type | 文字列 | テーブルデータの列の移動を行う。 | "sortColumn" |
| map | オブジェクト | 列の移動前後の位置を列番号でマッピングしたオブジェクト。{元の列番号:移動後の列番号}の形式 | {"0":1,"1":0,"2":2,"3":3} |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| List | 配列 | 変換後のテーブルデータ | [['name', 'age'], ['john', 30]] |
使用例
age 列の値が20以上の行を出力する。
+convert_table_1:
action>: ConvertTable
header: true
table: [['name', 'age'],['bob', 10], ['john', 30]]
transform: [
{
type: 'filter',
column: 'age',
operator: '>=',
operand: 20,
include_blank: true,
}
]
# => [['name', 'age'], ['john', 30]]
ヘッダーを['name', 'age'] から ['名前', '年齢']へ変更する。
+convert_table_1:
action>: ConvertTable
header: true
table: [['name', 'age'], ['bob', 10], ['john', 30]]
transform: [
{
type: 'column',
columns: {
name: '名前',
age: '年齢'
}
}
]
# => [['名前', '年齢'],['bob', 10],['john', 30]]
['名前', '年齢']というヘッダー行をテーブルデータに追加する。
+convert_table_1:
action>: ConvertTable
header: false
table: [['bob', 10], ['john', 30]]
transform: [
{
type: 'column',
columns: {
0: '名前',
1: '年齢'
}
}
]
# => [['名前', '年齢'],['bob', 10],['john', 30]]
name 列のみ抽出する。
+convert_table_1:
action>: ConvertTable
header: true
table: [['name', 'age'],['bob', 10],['john', 30]]
transform: [
{
type: 'column',
columns: {
name: 'name'
}
}
]
# => [['name'],['bob'],['john']]
['name', 'age'] の列を移動し ['age', 'name'] にする。
+convert_table_1:
action>: ConvertTable
header: true
table: [['name', 'age'], ['bob', 10], ['john', 30]]
transform: [
{
type: "sortColumn",
map: {
"0": 1,
"1": 0
}
}
]
# => [['age', 'name'],[10, 'bob'],[30, 'john']]
ConvertJSONToArray
概要
ConvertJSONToArray は、JSON をテーブルデータ(二次元配列)に変換して返すアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| json* | JSON または JSON 配列 | 変換元の JSON | ※使用例のサンプル JSON 参照 |
| header* | 配列 | 出力する配列のヘッダーに指定したい json のキーを、配列で入力 | ※使用例の yaml 参照 |
| unwind | 配列 | 行に分割したい配列のキーをパス指定し、配列で入力 | ※使用例の yaml 参照 |
| stringify | 配列 | 文字列化したい配列のキーをパス指定し、配列で入力 | ※使用例の yaml 参照 |
アクションのアウトプットを json に指定し、ピッカーで header や他パラメータを選択する
アクションのアウトプットを json に指定し、ピッカーで header を選択する場合、入力するアクションが実行済みである必要があります。 またピッカーで配列が value の key を header に選択すると、カラム名の横にメニューボタンが現れ、メニューから配列の処理方法を選択できます。
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Array | 配列 | ヘッダつきの二次元配列 | ※使用例のアウトプット参照 |
使用例
サンプル JSON
{
"data": [
{
"name": "プロモーションA",
"id": "abcde",
"id_data": [
{
"impressions": [10, 20, 30],
"installs": 1,
"date": "2021-01-01"
},
{
"impressions": [40, 50, 60],
"installs": 2,
"date": "2021-01-02"
}
]
},
{
"name": "プロモーションB",
"id": "fghij",
"id_data": [
{
"impressions": [100, 200, 300],
"installs": 10,
"date": "2021-01-01"
},
{
"impressions": [150, 250, 350],
"installs": 15,
"date": "2021-01-02"
}
]
}
]
}
上記サンプル JSON をデータ行が1行のフラットな二次元配列に変換する。
value に配列がある場合は各要素を列に展開する。
+convert_json_to_array_1:
action>: ConvertJSONToArray
json: sampleJSON
header: ["data.name","data.id","data.id_data.impressions","data.id_data.installs","data.id_data.date"]
unwind: []
stringify: []
# => [
# [
# "data.name",
# "data.id",
# "data.id_data.impressions.0",
# "data.id_data.impressions.1",
# "data.id_data.impressions.2",
# "data.id_data.installs",
# "data.id_data.date"
# ],
# [
# "プロモーションA",
# "abcde",
# 10,
# 20,
# 30,
# 1,
# "2021-01-01"
# ],
# [
# "プロモーションA",
# "abcde",
# 40,
# 50,
# 60,
# 2,
# "2021-01-02"
# ],
# [
# "プロモーションB",
# "fghij",
# 100,
# 200,
# 300,
# 10,
# "2021-01-01"
# ],
# [
# "プロモーションB",
# "fghij",
# 150,
# 250,
# 350,
# 15,
# "2021-01-02"
# ]
# ]
上記サンプル JSON において配列の各要素を行に展開した二次元配列に変換する。
各要素を行に展開したい配列を value に持つ key を unwind に指定する。
+convert_json_to_array_1:
action>: ConvertJSONToArray
json: sampleJSON
header: ["data.name","data.id","data.id_data.impressions","data.id_data.installs","data.id_data.date"]
unwind: ["data.id_data.impressions"]
stringify: []
# => [
# [
# "data.name",
# "data.id",
# "data.id_data.impressions",
# "data.id_data.installs",
# "data.id_data.date"
# ],
# [
# "プロモーションA",
# "abcde",
# 10,
# 1,
# "2021-01-01"
# ],
# [
# "プロモーションA",
# "abcde",
# 20,
# 1,
# "2021-01-01"
# ],
# [
# "プロモーションA",
# "abcde",
# 30,
# 1,
# "2021-01-01"
# ],
# [
# "プロモーションA",
# "abcde",
# 40,
# 2,
# "2021-01-02"
# ],
# [
# "プロモーションA",
# "abcde",
# 50,
# 2,
# "2021-01-02"
# ],
# [
# "プロモーションA",
# "abcde",
# 60,
# 2,
# "2021-01-02"
# ],
# [
# "プロモーションB",
# "fghij",
# 100,
# 10,
# "2021-01-01"
# ],
# [
# "プロモーションB",
# "fghij",
# 200,
# 10,
# "2021-01-01"
# ],
# [
# "プロモーションB",
# "fghij",
# 300,
# 10,
# "2021-01-01"
# ],
# [
# "プロモーションB",
# "fghij",
# 150,
# 15,
# "2021-01-02"
# ],
# [
# "プロモーションB",
# "fghij",
# 250,
# 15,
# "2021-01-02"
# ],
# [
# "プロモーションB",
# "fghij",
# 350,
# 15,
# "2021-01-02"
# ]
# ]
上記サンプル JSON において配列を文字列化して二次元配列に変換する。
文字列化したい配列を value に持つ key を stringify に指定する。
+convert_json_to_array_1:
action>: ConvertJSONToArray
json: sampleJSON
header: ["data.name","data.id","data.id_data.impressions","data.id_data.installs","data.id_data.date"]
unwind: []
stringify: ["data.id_data.impressions"]
# => [
# [
# "data.name",
# "data.id",
# "data.id_data.impressions",
# "data.id_data.installs",
# "data.id_data.date"
# ],
# [
# "プロモーションA",
# "abcde",
# "[10,20,30]",
# 1,
# "2021-01-01"
# ],
# [
# "プロモーションA",
# "abcde",
# "[40,50,60]",
# 2,
# "2021-01-02"
# ],
# [
# "プロモーションB",
# "fghij",
# "[100,200,300]",
# 10,
# "2021-01-01"
# ],
# [
# "プロモーションB",
# "fghij",
# "[150,250,350]",
# 15,
# "2021-01-02"
# ]
# ]
CompareTable
概要
ComparaTableは、二つのテーブルデータ(二次元配列)を比較し、合成または差分を抽出するアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| leftTerm* | 配列 | 比較元のテーブルデータ | [["name", "age"],["bob", 10], ["john", 30], ["ken", 40]] |
| rightTerm* | 配列 | 比較先のテーブルデータ | [["name", "address"],["john", "Tokyo"], ["ken", "Saitama"]] |
| method* | 文字列 | 演算方式を選択する。合成の場合はadd。差分を求める場合はsubtract | add |
| identifier | 文字列 | 比較元のテーブルの同一性を確認する(keyとなる)列を指定する | A |
| header* | 真偽値 | テーブルにヘッダーが存在する場合はtrue、そうでない場合はfalse | true |
アクションのアウトプットを leftTerm に指定し、ピッカーで identifier を選択する
アクションのアウトプットを leftTerm に指定し、ピッカーで identifier を選択する場合、入力するアクションが実行済みである必要があります。
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Array | 配列 | 二次元配列 | [["name", "age", "address"],["bob", 10, ""],["john", 30, "Tokyo"],["ken", 40, "Saitama"]] |
使用例1
A列("name")をkeyとしてテーブルを合成(add)する。
+compare_table_1:
action>: CompareTable
leftTerm: [["name","age"],["bob",10],["jane",30],["adam",20]]
rightTerm: [["name","addr"],["bob","saitama"],["jane","newyork"],["ken","yamaguchi"]]
method: add
identifier: A
header: true
# => [["name","age","addr"],["bob",10,"saitama"],["jane",30,"newyork"],["adam",20,""],["ken","","yamaguchi"]]
leftTerm
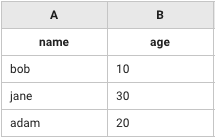
rightTerm
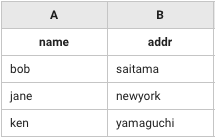
アウトプット
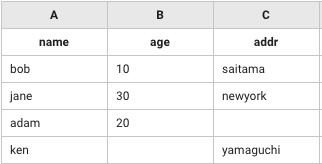
使用例2
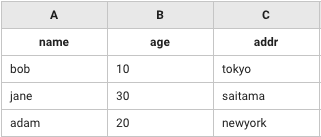
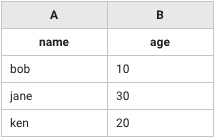
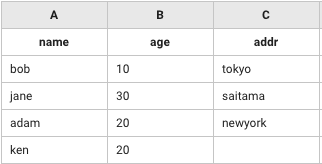
A列("name")とB列("age")をkeyとしてテーブルを合成(add)する。
+compare_table_1:
action>: CompareTable
leftTerm: [["name","age","addr"],["bob",10,"tokyo"],["jane",30,"saitama"],["adam",20,"newyork"]]
rightTerm: [["name","age"],["bob",10],["jane",30],["ken",20]]
method: add
identifier: 'A&B'
header: true
# => [["name","age","addr"],["bob",10,"tokyo"],["jane",30,"saitama"],["adam",20,"newyork"],["ken",20,""]]
leftTerm
rightTerm
アウトプット
使用例3
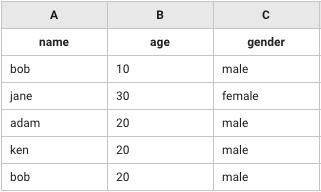
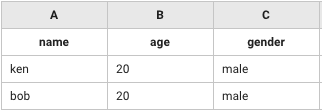
A列("name")、B列("age")、C列("gender")をkeyとしてテーブルの差分を抽出(subtract)する。
+compare_table_1:
action>: CompareTable
leftTerm: [["name","age","gender"],["bob",10,"male"],["jane",30,"female"],["adam",20,"male"],["ken",20,"male"],["bob",20,"male"]]
rightTerm: [["name","age","gender"],["bob",10,"male"],["jane",30,"female"],["adam",20,"male"]]
method: subtract
identifier: 'A&B&C'
header: true
# => [["name","age","gender"],["ken",20,"male"],["bob",20,"male"]]
leftTerm
rightTerm
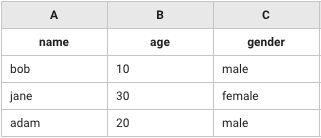
アウトプット
DataStoreSave
概要
DataStoreSaveは、プロジェクト間で共有可能なデータストアに、データを保存するアクションです。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| key* | 文字列 | 保存するデータの名前。同じキーのデータは上書きされます | last_id |
| value* | 任意 | 保存するデータの中身。データの形式は文字列や配列など任意。 | 1 |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 任意 | 保存したデータのvalue | [["name", "age"], ["bob", 10]] |
使用例
# データを保存する
+data_store_save_1:
action>: DataStoreSave
key: last_id
value: 1
DataStoreGet
概要
DataStoreGetは、プロジェクト間で共有可能なデータストアから、データを取得するアクションです。 指定したkeyのデータが見つからない場合はfalseが返り、実行中のワークフローは継続されます。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| key* | 文字列 | 取得するデータの名前 | last_id |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Anything | 任意 | 取得したデータのvalue。 データが見つからない場合false | 1 |
使用例
# データを取得する
+data_store_get_1:
action>: DataStoreGet
key: last_id
DataStoreDelete
概要
DataStoreDeleteは、プロジェクト間で共有可能なデータストアから、データを削除するアクションです。 指定したkeyのデータが見つからない場合、エラーになります。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| key* | 文字列 | 削除したいデータの名前 | last_id |
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Boolean | 真偽値 | 成功した場合はtrue、失敗した場合はエラーになる | true |
使用例
# データを削除する
+data_store_delete_1:
action>: DataStoreDelete
key: last_id
AggregateData
概要
二次元配列形式の表データを集計するアクションです。 合計、平均、件数、一意件数、標本分散、標本標準偏差、最大値、最小値 に対応しています。
※こちらはプレビューリリースのため、将来的に仕様が変更される可能性があります。また、デスクトップ版未対応です。
パラメーター
*は、必須パラメーター
| 名前 | 型 | 概要 | 例 |
|---|---|---|---|
| table* | 配列 | 集計したい表データ(二次元配列) | [["生年月", "名前", "性別", "国語", "数学"],["2012年02月", "佐藤 一郎", "男性", "53", "10"], ["2012年12月", "鈴木 絵里", "女性", "78", "2"]] |
| hasHeader* | 真偽値 | true にすると、一行目がヘッダーとして利用されます。テーブルにヘッダー行が存在しない場合は、false にすることで、ヘッダーを連番で作成します。 | true |
| groupby | 配列 | グループ化したい列を指定します。指定がない場合は、すべてのデータを一つのグループにします。集計列(columns)と指定が被る場合は、groupbyが優先されます。 | ["生年月","性別"] |
| columns | 配列 | 集計したい列を指定します。指定がない場合は、集計可能なすべての列を集計します。 | ["国語","数学"] |
| calculations | 配列 | 集計方法を指定します。指定がない場合は、集計可能なすべての計算を実施します。 | ["mean","sum"] |
| skipna* | 真偽値 | 欠損値や NaN(集計可能ではない値)をスキップするかどうかを指定します。false の場合は、NaNをスキップしないようにするため、集計結果は、NaN となります。データに欠損値や NaN が含まれていることを期待していない時は、false を指定すると安全です。 | false |
| fillna | 数値 | 欠損値や NaN(集計可能ではない値)を別の数値で埋めることができます。例えば、0 とするとすべての欠損値は 0 に置き換えられます。fillna を指定すると NaN が存在しなくなるため skipna は、無効になります。これは特に平均値の計算で重要になります。平均する分母に欠損値を含めたくない場合は、fillna の指定はせず、skipna を true としてください。 | 0 |
| outputArray* | 真偽値 | true にすると配列形式、falseのときはJSONで出力されます。 | true |
ピッカーで 集計する列 を選択する
tableにデータがあるとき、goupby, columns, calculations はピッカーで集計する列を選択することができます。
アウトプット
| タイプ | 型 | 概要 | 例 |
|---|---|---|---|
| Array | 配列 | 集計した結果のテーブル(二次元配列) | [["Type", "生年月", "性別", "国語", "数学"], ["平均", "2012年02月", "男性", "53", "10"], ["平均", "2012年12月", "女性", "78", "2"]] |
使用例
# データを集計する
+aggregate_data_1:
action>: AggregateData
table: [["生年月","名前","性別","国語","数学"],["2012年02月","佐藤 一郎","男性","53","10"],["2012年12月","鈴木 絵里","女性","78","2"],["2012年03月","高橋 翔太","男性","29","27"]]
hasHeader: true
groupby: ["生年月","性別"]
columns: ["国語","数学"]
calculations: ["mean","sum"]
skipna: false
fillna: '0'
outputArray: true
private: false
meta:
display:
calculations:
label: '平均, 合計'
type: chip
icon: calculate
groupby:
label: '生年月, 性別'
type: chip
icon: intentionaryBlank
columns:
label: '国語, 数学'
type: chip
icon: intentionaryBlank
# =>
# [
# [
# "Type",
# "生年月",
# "性別",
# "国語",
# "数学"
# ],
# [
# "平均",
# "2012年02月",
# "男性",
# "53",
# "10"
# ],
# [
# "平均",
# "2012年12月",
# "女性",
# "78",
# "2"
# ],
# [
# "平均",
# "2012年03月",
# "男性",
# "29",
# "27"
# ],
# [
# "合計",
# "2012年02月",
# "男性",
# "53",
# "10"
# ],
# [
# "合計",
# "2012年12月",
# "女性",
# "78",
# "2"
# ],
# [
# "合計",
# "2012年03月",
# "男性",
# "29",
# "27"
# ]
# ]